
Elastic Stack入门
本文根据慕课网教程《Elastic Stack入门》 结合当前我的实际情况进行整理。
当前时间:2018.04.11
环境介绍:
服务器:2台阿里云服务器CentOS7.4 64位 2核8G
server-1: 内网IP:172.16.1.2 公网IP:47.93.32.28
server-2: 内网IP:172.16.1.4 公网IP:39.105.19.68
使用2台服务器,模拟在生产时集群的情况。
说明:由于是在云上,你的安全组规则需要打开对应的端口,我这里为了测试方便,已经设置安全组所有端口全部对外开放。
目录说明:
由于是在云上,你可能会单独挂载一块数据盘,这块数据盘我挂载到/data目录下,所以之后的操作数据都会存到/data目录下。
创建所需的目录:mkdir -p /data/{software,app}
/data/software/ 我用于存放软件的安装包等
/data/app/ 我用于存放软件的运行目录
用到的软件及版本:
jdk:jdk-8u161-linux-x64.tar.gz
elasticsearch:https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.2.3.tar.gz
kibana:https://artifacts.elastic.co/downloads/kibana/kibana-6.2.3-linux-x86_64.tar.gz
filebeat:https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.2.3-linux-x86_64.tar.gz
logstash:https://artifacts.elastic.co/downloads/logstash/logstash-6.2.3.tar.gz
cerebro:https://github.com/lmenezes/cerebro
第一章:Elastic Stack介绍
ELK相信大家都听说过,ELK即(elasticsearch,logstash,kibanna),后来Beats的引入,他们现在统称为了Elastic Stack。
开源的 Elastic Stack能够安全可靠地获取任何来源、任何格式的数据,并且能够实时地对数据进行搜索、分析和可视化。能够帮助您解决您的 日志,应用搜索,站内搜索,安全分析,指标监控,应用性能分析,甚至更多。
第二章:Elasticsearch和Kibanna入门
Server-1安装
jdk安装:
将下载好的jdk安装包jdk-8u161-linux-x64.tar.gz上传到/data/software/目录下。
cd /data/software/
tar -zxvf jdk-8u161-linux-x64.tar.gz
mv jdk1.8.0_161/ /data/app/
cd /data/app/
ln -s jdk1.8.0_161/ java
[root@iZ2zedrl9ahkaawkt16ylwZ app]# ll
total 4
lrwxrwxrwx 1 root root 13 Apr 11 11:42 java -> jdk1.8.0_161/
drwxr-xr-x 8 10 143 4096 Dec 20 08:24 jdk1.8.0_161
配置环境变量:
vim /etc/profile
将以下加到文件末尾,保存退出。
export JAVA_HOME=/data/app/java/
export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH执行 source /etc/profile 即时生效。
查看java版本:
[root@iZ2zedrl9ahkaawkt16ylwZ app]# java -version
java version "1.8.0_161"
Java(TM) SE Runtime Environment (build 1.8.0_161-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.161-b12, mixed mode)Elasticsearch安装:
cd /data/software/
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.2.3.tar.gz
tar -zxvf elasticsearch-6.2.3.tar.gz
mv elasticsearch-6.2.3 /data/app/
启动前准备:
启动elasticsearch不能使用root用户启动,所以这里需要单独建一个用户 elastic ,并授权。
useradd elastic
chown -R elastic.elastic /data/app/elasticsearch-6.2.3/
另外还需要创建两个目录用于存放elasticsearch的数据和日志:
mkdir /data/es-data/
mkdir /data/es-log/
chown -R elastic.elastic /data/es-data/
chown -R elastic.elastic /data/es-log/
配置elasticsearch:
切换到elastic用户下操作:
su - elastic
cd /data/app/elasticsearch-6.2.3/config/
目录下有3个文件:
elasticsearch.yml 和elasticsearch配置相关
jvm.options 和jvm的一些参数相关,如调整内存大小
log4j2.properties 和elasticsearch的日志相关,一般情况不会修改它
配置elasticsearch.yml
主要配置以下几个参数:
cluster.name: es-cluster #集群的名字,集群里所有节点都应该改为同样的名字
node.name: es-node-1 #集群中当前本机的节点名字
path.data: /data/es-data #es数据存放位置
path.logs: /data/es-log #es日志存放位置
network.host: 172.16.1.2 #本机的内网IP
http.port: 9200 #监听的端口
discovery.zen.ping.unicast.hosts: ["172.16.1.2","172.16.1.4"] #集群节点发现,需要将集群的节点IP写入到这里。
关于Development与Production模式的说明:
从es5.x开始,es在启动的时候会做一些检查,Development模式和Production模式是不一样的。
判断标准:以transport的地址是否绑定在localhost为判断标准,即network.host默认是localhost或127.0.0.1,则表示为Development模式,如果写成了一个实实在在具体的ip地址,则表示是Production模式
Development模式下载启动的时候会以warning的方式提示配置检查异常
Production模式下启动时会以error的方式提示配置检查异常并退出
修改完成后,这时启动的话还会遇到以下两个错误问题:
[1]: max file descriptors [65535] for elasticsearch process is too low, increase to at least [65536]
解决办法:
vim /etc/security/limits.conf
添加以下到文件末尾:
* - nofile 65536
* - memlock unlimited
[2]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
解决办法:
vim /etc/sysctl.conf
添加以下到文件末尾:
vm.max_map_count=262144
保存后,执行 sysctl -p 生效。
配置jvm.options
这里我不需要修改。
启动elasticsearch(记得在elastic用户下):
cd /data/app/elasticsearch-6.2.3/bin/
./elasticsearch
启动后便可通过 http://ip:9200/ 进行访问了。
我这里是 http://47.93.32.28:9200/ 如下:
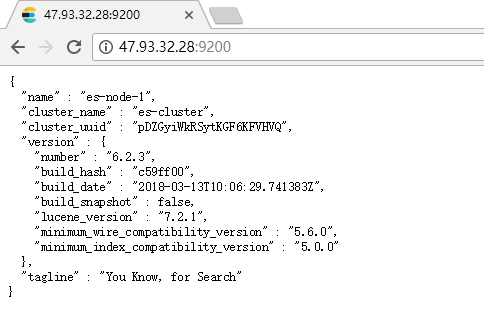
Server-2安装
安装方式和Server-1一样,只需在配置的时候注意修改配置,Server-2的配置如下:
cluster.name: es-cluster
node.name: es-node-2
path.data: /data/es-data
path.logs: /data/es-log
network.host: 172.16.1.4
http.port: 9200
discovery.zen.ping.unicast.hosts: ["172.16.1.2","172.16.1.4"]
启动后访问:http://39.105.19.68:9200/ 如下:
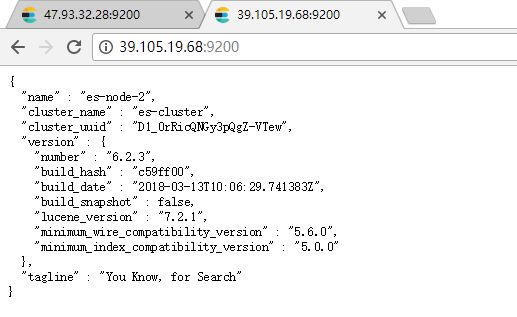
查看集群可通过访问API进行查看:http://47.93.32.28:9200/_cat/nodes

查看是输出标题栏:http://47.93.32.28:9200/_cat/nodes?v
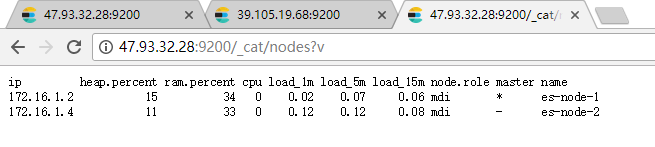
master那一列,*号表示是主节点。
查看集群详细信息:http://47.93.32.28:9200/_cluster/stats
如何在单台机器上启动集群例子:
在单机上启动集群需要保证端口不一样,以及存储数据的目录不一样。生产系统上不建议在单机上启动集群,没有意义,这里仅做测试。
bin/elasticsearch #启动第一个默认实例,监听9200端口
bin/elasticsearch -Ehttp.port=8200 -Epath.data=node2 #启动第2个默认实例,监听端口8200,数据存在node2下
bin/elasticsearch -Ehttp.port=7200 -Epath.data=node3 #启动第3个默认实例,监听端口7200,数据存在node3下
通过以上3条启动语句便实现在单机上启动集群。
Kibanna入门
安装Kibanna只需要在其中一台机器上安装即可,这里我安装在server-1上。
在server-1上:
cd /data/software/
wget https://artifacts.elastic.co/downloads/kibana/kibana-6.2.3-linux-x86_64.tar.gz
tar -zxvf kibana-6.2.3-linux-x86_64.tar.gz
mv kibana-6.2.3-linux-x86_64 /data/app/
配置Kibanna:
cd /data/app/kibana-6.2.3-linux-x86_64/config/
只有1个配置文件 kibana.yml ,主要配置以下参数:
server.port: 5601 #kibanna监听的端口
server.host: "172.16.1.2" #server的ip
elasticsearch.url: "http://172.16.1.2:9200" #Kibanna要与哪个elasticsearch进行连接
启动Kibanna:
cd /data/app/kibana-6.2.3-linux-x86_64/bin/
./kibana
启动成功后访问地址:http://47.93.32.28:5601/ 即可访问。
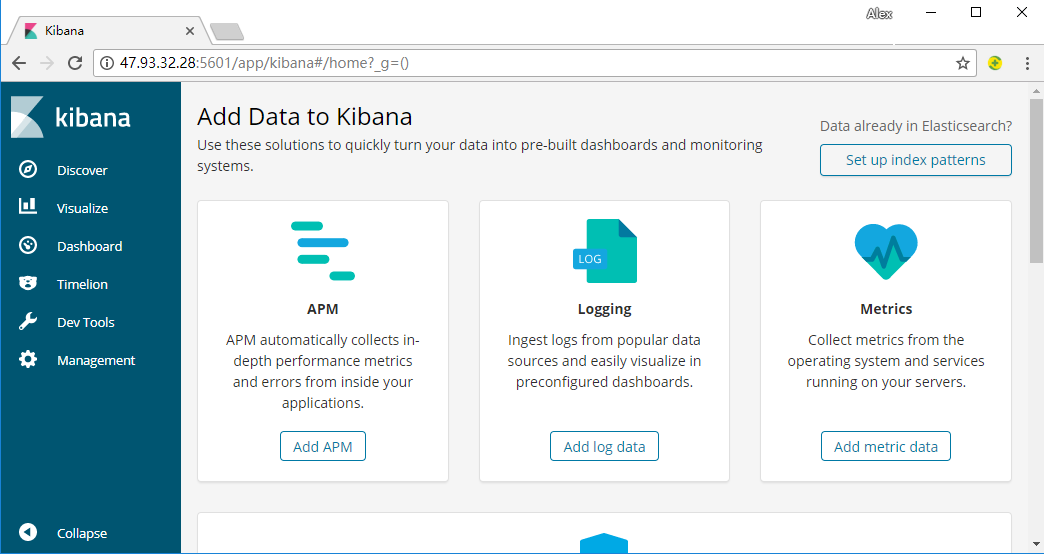
界面说明:
Discover:数据搜索查看
Visualize:图表制作
Dashboard:仪表盘制作
Timelion:时序数据的高级可视化分析
DevTools:开发者工具
Management:配置
Elasticsearch常用术语:
Document:文档数据,指的是我们存在elasticsearch中的一条数据
Index:索引,可理解为在mysql中的一个数据库,所有的document都是存在一个具体的索引中的,Index下可以有多个type。但在6.x后一个index下只能有一个type,所以理解为数据库名字已经不太合适了,可以理解为表
Type:索引中的数据类型,可以理解为mysql库中的一个表
Field:字段,文档的属性
Query DSL:查询语法
Elasticsearch CRUD
CRUD表示:
Create:创建文档
Read:读取文档
Update:更新文档
Delete:删除文档
接下来我们利用语句在Kibanna中进行增删改查:
Elasticsearch Create:
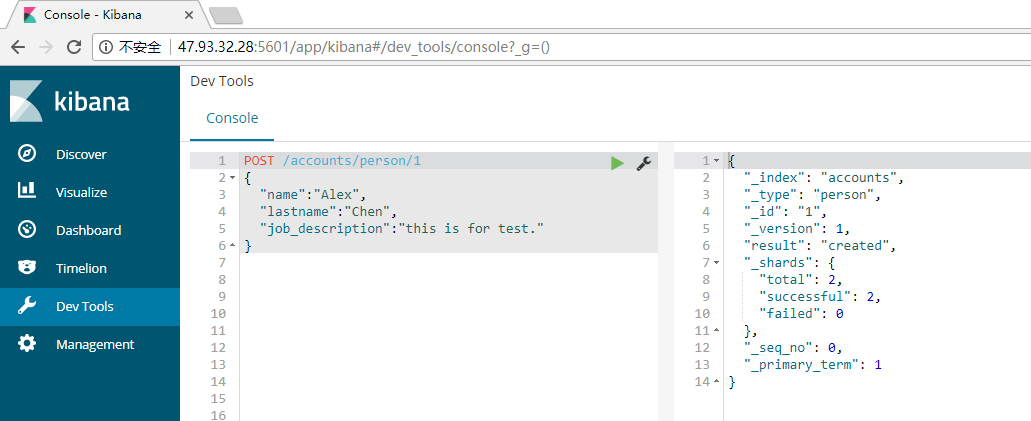
如上图所示,在Console中,左边是语句输入窗口,右边是执行结果。
我们通过一个POST请求进行了1个文档的创建,其中account表示索引,person表示类型,1表示这个文档的id。
POST /accounts/person/1
{
"name":"Alex",
"lastname":"Chen",
"job_description":"this is for test."
}
Elasticsearch Read:
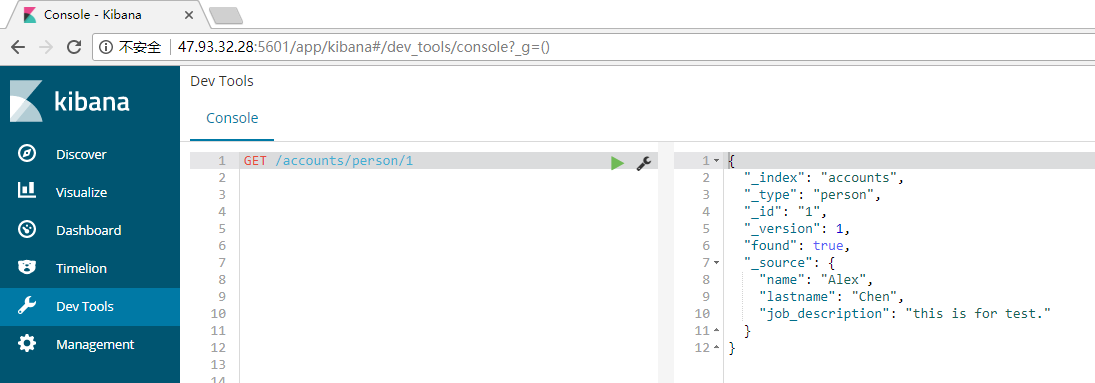
通过GET请求,获取accounts索引下,person类型,文档id为1的信息。
GET /accounts/person/1
Elasticsearch Update:
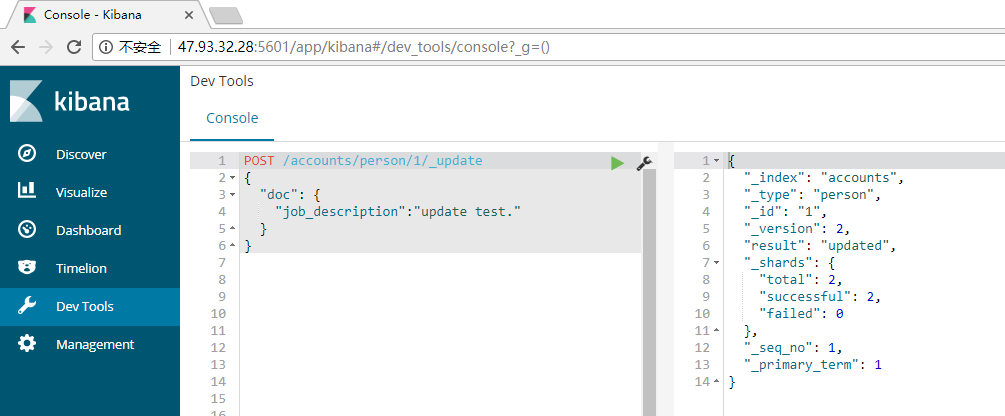
通过POST请求和_update来对文档进行更新。这里我将job_description的值改为了update test
POST /accounts/person/1/_update
{
"doc": {
"job_description":"update test."
}
}查询一下修改后的文档,已经修改成功:
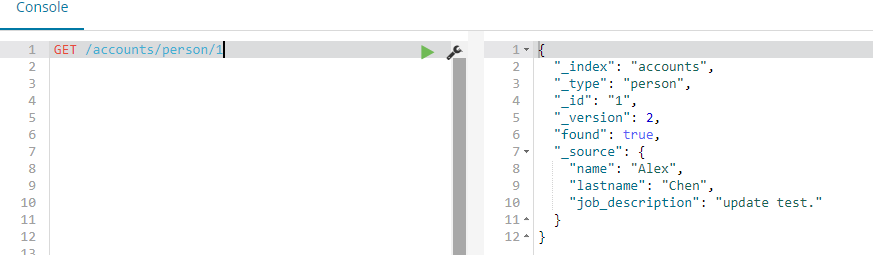
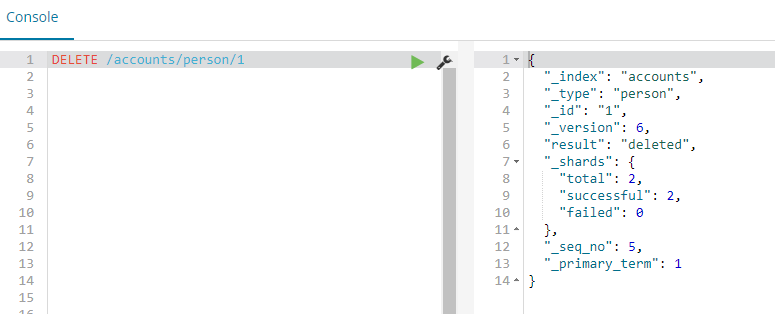
Elasticsearch Delete:
DELETE /accounts/person/1 #删除指定的文档
DELETE /accounts #删除指定的索引

Elasticsearch Query
Query String
形式:
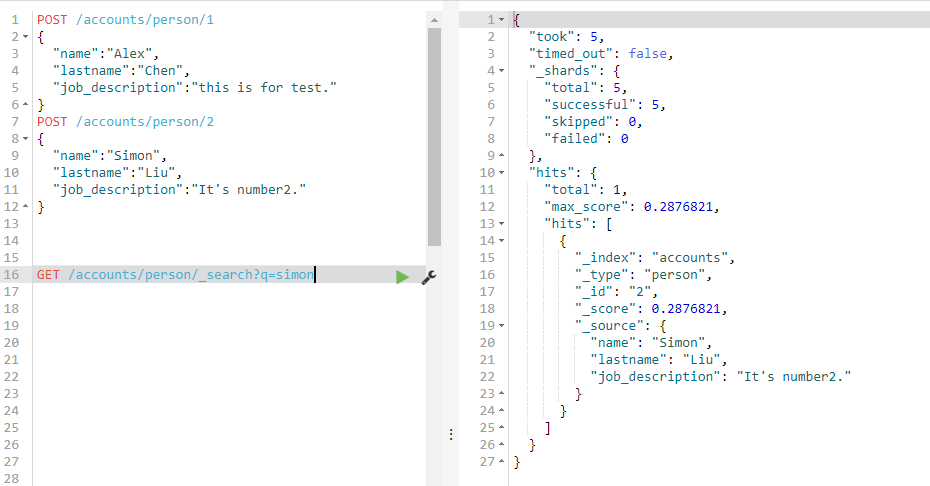
GET /accounts/person/_search?q=simon
如下:首先通过POST创建了2个文档,然后使用Query String的方式查询simon,右边输出了查询到的结果。
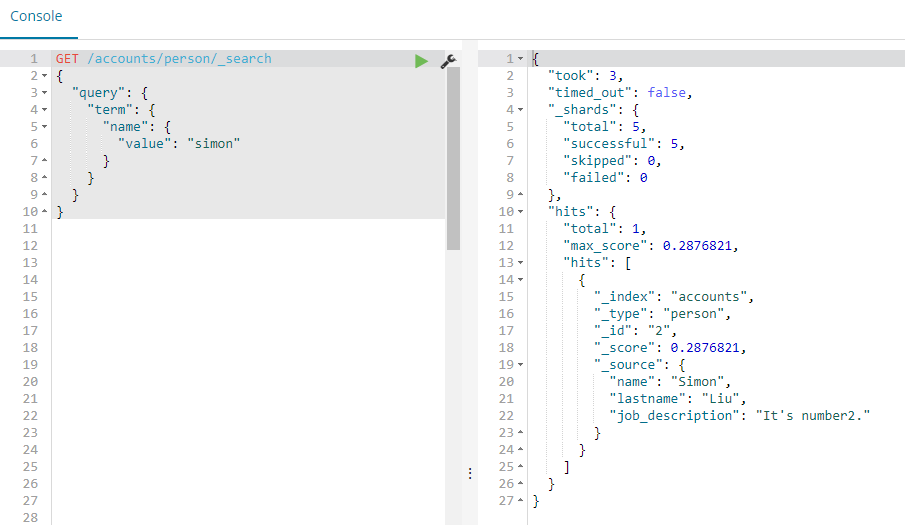
Query DSL
形式:
GET /accounts/person/_search
{
"query": {
"term": {
"name": {
"value": "simon"
}
}
}
}
更多使用方法,请访问Elasticsearch官网:https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
第三章:Beats、Filebeat入门
Beats介绍
Beats 平台集合了多种单一用途数据采集器。这些采集器安装后可用作轻量型代理,从成百上千或成千上万台机器向 Logstash 或 Elasticsearch 发送数据。
Beats系列的产品包括:
-Filebeat:日志文件
-Metricbeat:度量数据
-Packetbeat:网络数据
-Winlogbeat:Windows数据
-Auditbeat:审计数据
-Heartbeat:健康检查
Beats平台:
如下图,各个Beat可以将数据直接传到elasticsearch,也可以传入到logstash进行处理后传入elasticsearch,最后通过Kibanna进行友好的展现出来。
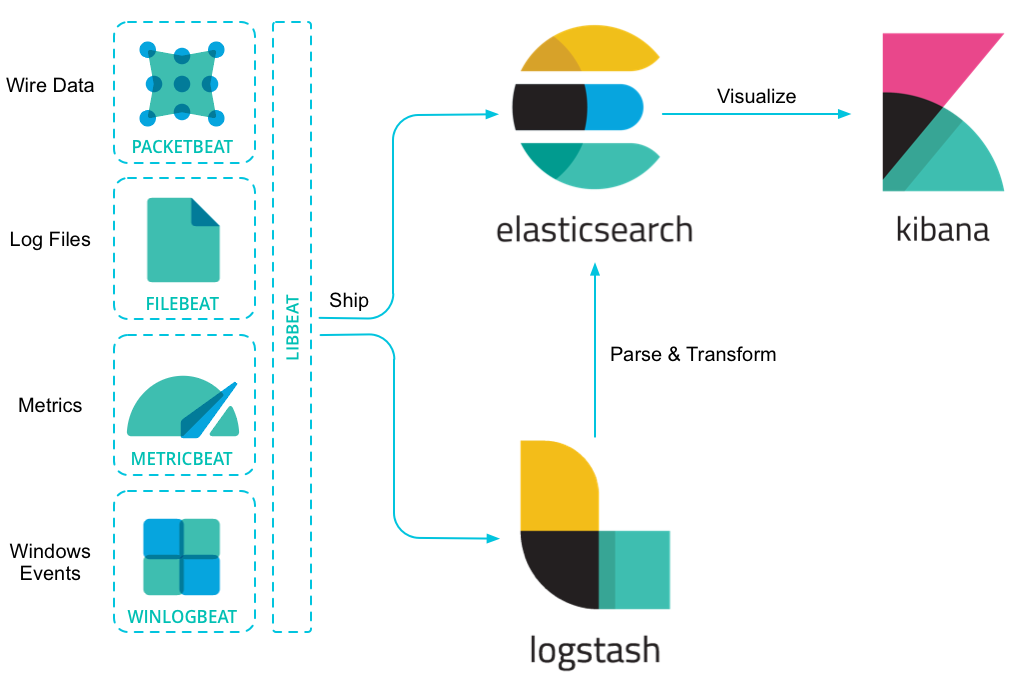
更多请查看官网:https://www.elastic.co/cn/products/beats
Filebeat入门
Filebeat处理流程:
输入 input
处理 Filter
输出 Output
如下图:
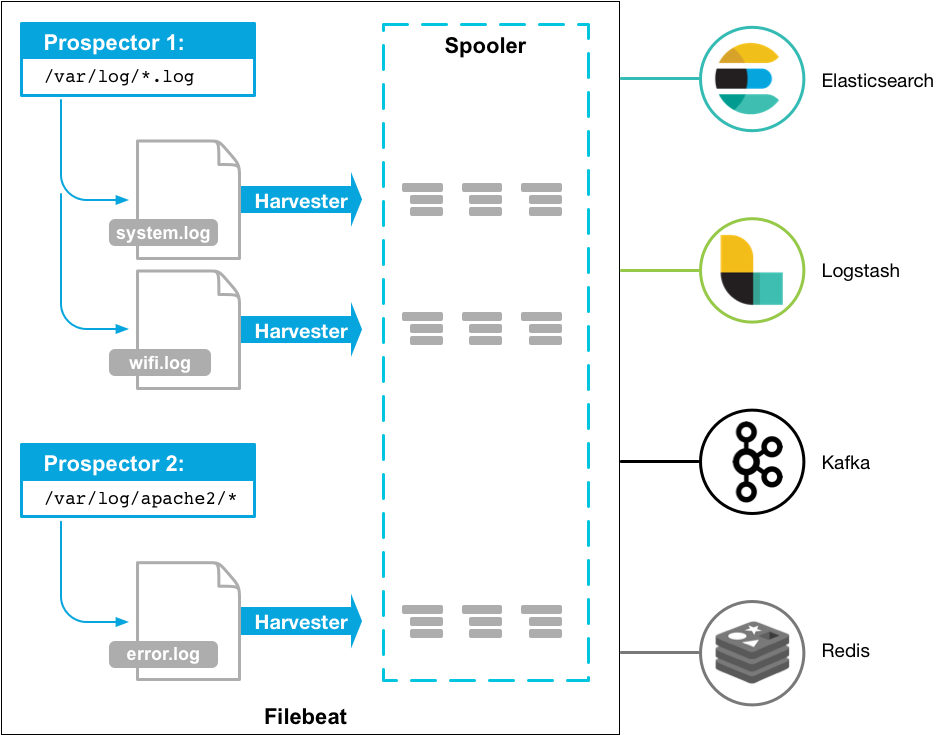
Filebeat安装:
我们将Filebeat安装在server-2机器上收集nginx的日志。
首先安装nginx:
yum install nginx
启动nginx:systemctl start nginx
访问地址:http://39.105.19.68/ 多访问几次使得日志文件中产生访问日志
日志在:
/var/log/nginx/access.log
/var/log/nginx/error.log
安装Filebeat:
cd /data/software/
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.2.3-linux-x86_64.tar.gz
tar -zxvf filebeat-6.2.3-linux-x86_64.tar.gz
mv filebeat-6.2.3-linux-x86_64 /data/app/
配置Filebeat:
cd /data/app/filebeat-6.2.3-linux-x86_64/
编辑配置文件 filebeat.yml ,主要配置以下:
- type: log
enabled: true
paths:
- /var/log/nginx/access.log
output.elasticsearch:
hosts: ["172.16.1.2:9200",“172.16.1.4:9200”]检索/var/log/nginx/目录下所有以 .log 结尾的日志文件。
输出到两个elasticsearch节点中。
启动Filebeat:
./filebeat -c filebeat.yml -e
启动成功后即可在Kibanna的Management中看到,Kibanna从Elasticsearch中获取到的索引。
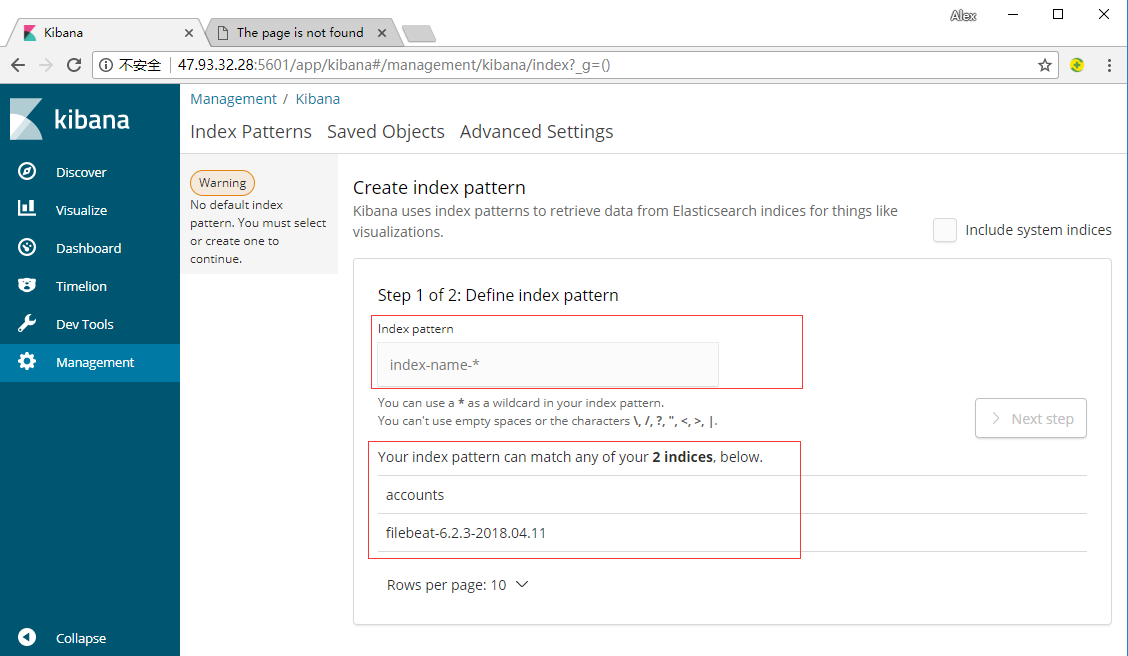
下面方框是当前已有的索引,上面方框是需要你填入的索引名称,如在上面输入filebeat后会自动匹配。
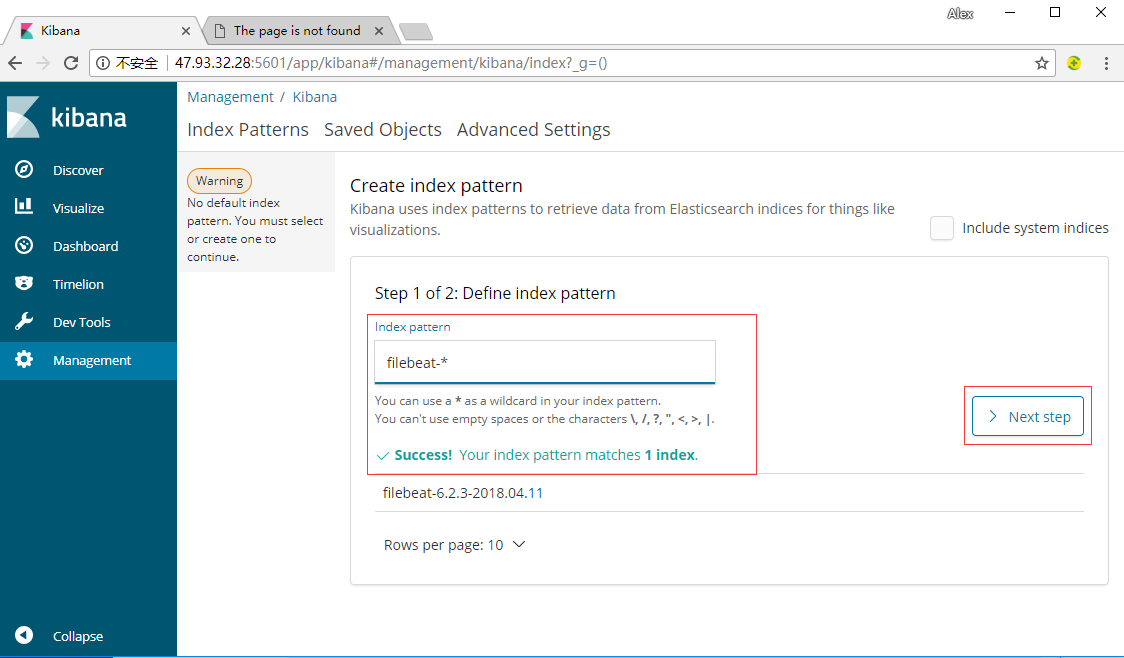
选择@timestamp
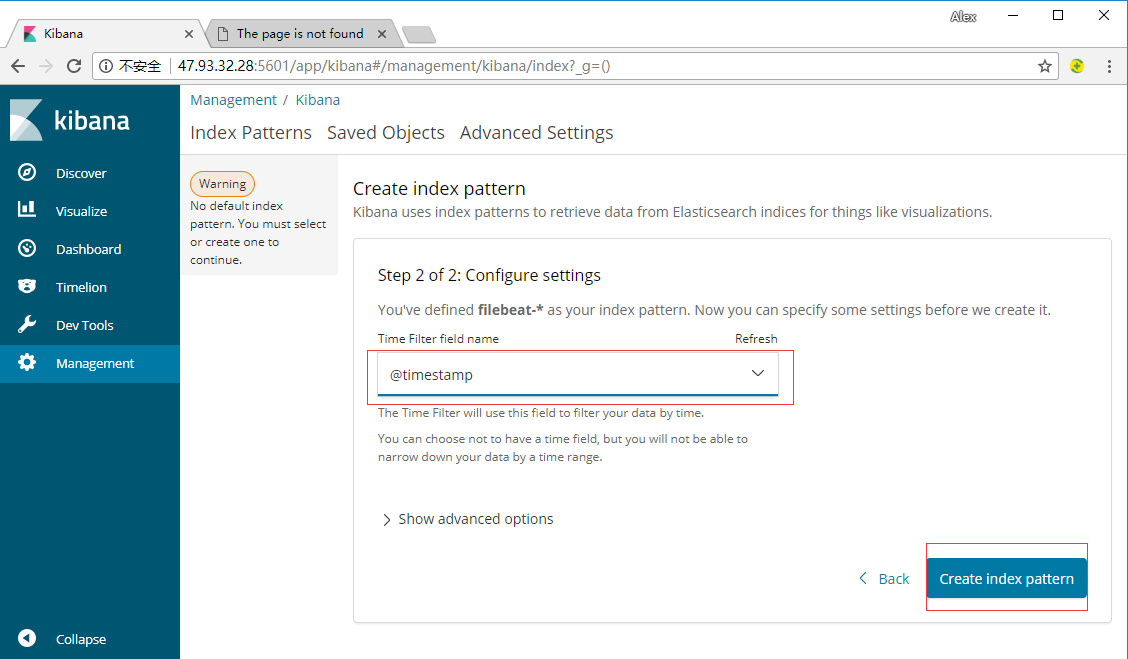
创建成功后即可在Discover中看到数据了。
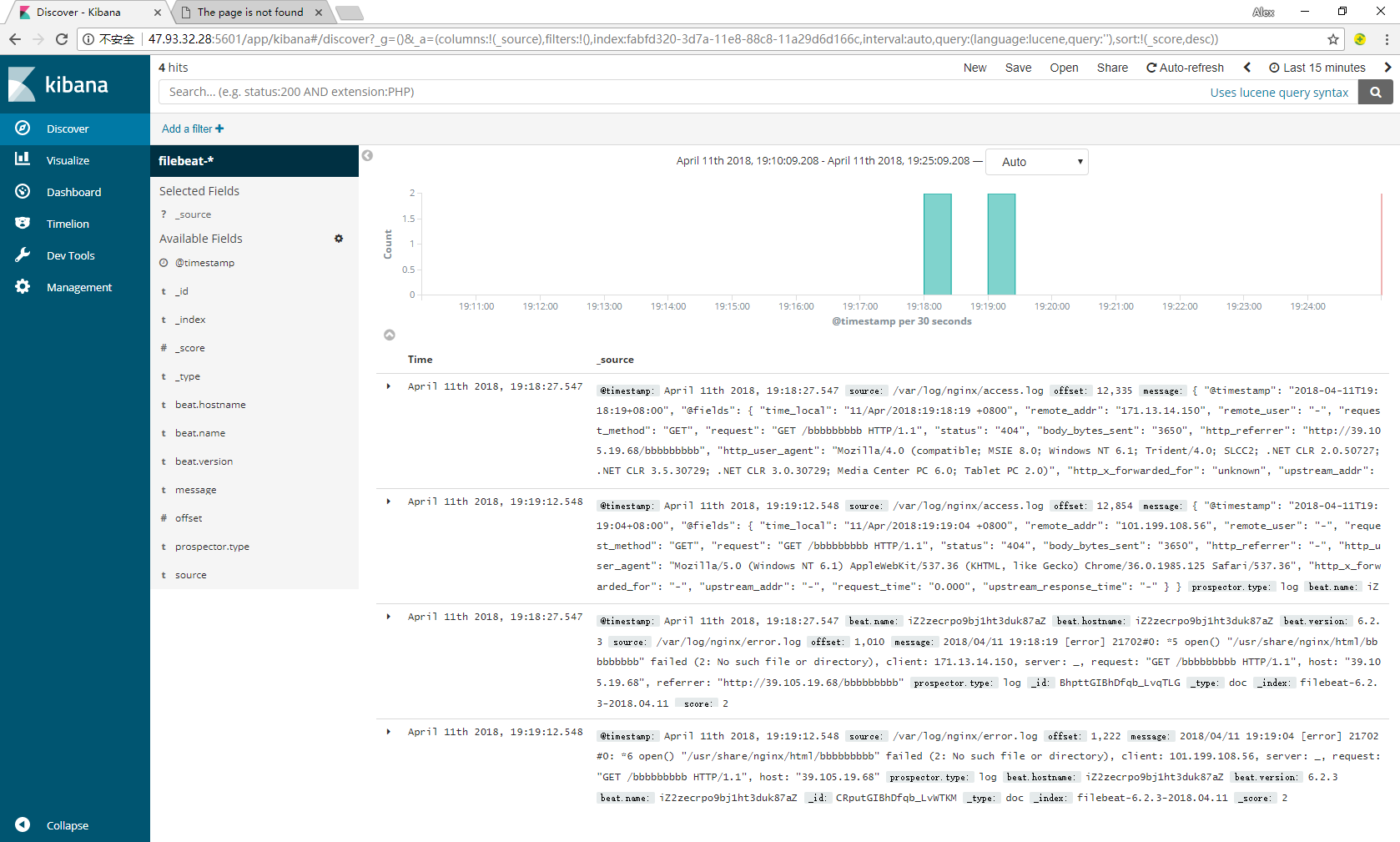
已上便实现了对nginx日志/var/log/nginx/access.log的收集,但是现在收集起来的日志不具备很好的统计分析能力,所有信息都在message里。
这里我们可以进行一些改造,首先配置nginx日志格式化输出为json格式,然后Filebeat再做收集,收集起来的日志就具备可分析能力。
改造nginx日志输出格式:
vim /etc/nginx/nginx.conf
新增以下到log_format下:
log_format json '{ "@timestamp": "$time_iso8601", '
'"@fields": { '
'"time_local": "$time_local", '
'"remote_addr": "$remote_addr", '
'"remote_user": "$remote_user", '
'"request_method": "$request_method", '
'"request": "$request", '
'"status": "$status", '
'"body_bytes_sent": "$body_bytes_sent", '
'"http_referrer": "$http_referer", '
'"http_user_agent": "$http_user_agent", '
'"http_x_forwarded_for": "$http_x_forwarded_for", '
'"upstream_addr": "$upstream_addr", '
'"request_time": "$request_time", '
'"upstream_response_time": "$upstream_response_time" } }';然后将 access_log /var/log/nginx/access.log main;
改为 access_log /var/log/nginx/access.log json;
重启nginx:systemctl restart nginx
此时访问 http://39.105.19.68/ 即可查看到nginx日志 /var/log/nginx/access.log 里输出的是json格式的日志了。
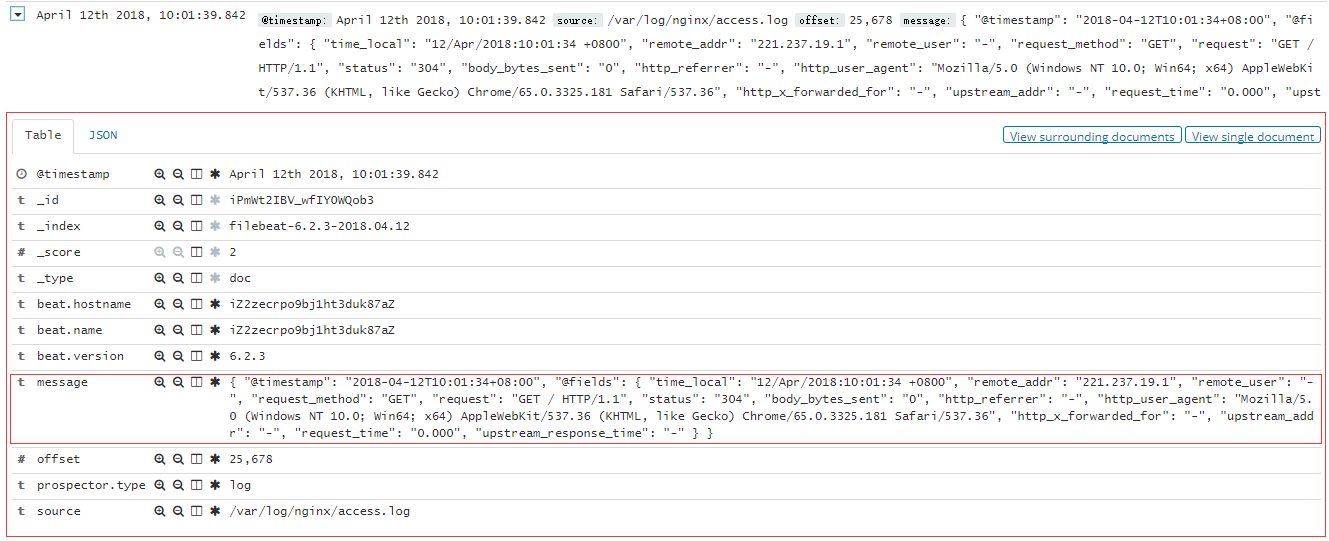
格式化后如下,很清楚的展示了访问的信息:
{
"@timestamp": "2018-04-12T10:01:34+08:00",
"@fields": {
"time_local": "12/Apr/2018:10:01:34 +0800",
"remote_addr": "221.237.19.1",
"remote_user": "-",
"request_method": "GET",
"request": "GET / HTTP/1.1",
"status": "304",
"body_bytes_sent": "0",
"http_referrer": "-",
"http_user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36",
"http_x_forwarded_for": "-",
"upstream_addr": "-",
"request_time": "0.000",
"upstream_response_time": "-"
}
}
接下来修改filebeat的配置:
修改filebeat.yml配置文件,添加:
json.message_key: log
json.keys_under_root: true
添加后如下:
- type: log
enabled: true
paths:
- /var/log/nginx/access.log
json.message_key: log
json.keys_under_root: true
output.elasticsearch:
hosts: ["172.16.1.2:9200","172.16.1.4:9200"]重启filebeat,然后查看Kibanna,现在即可看到已经将原来message中的信息变成了一个个字段,这样就可以让我们可以想mysql那样进行查询统计了。
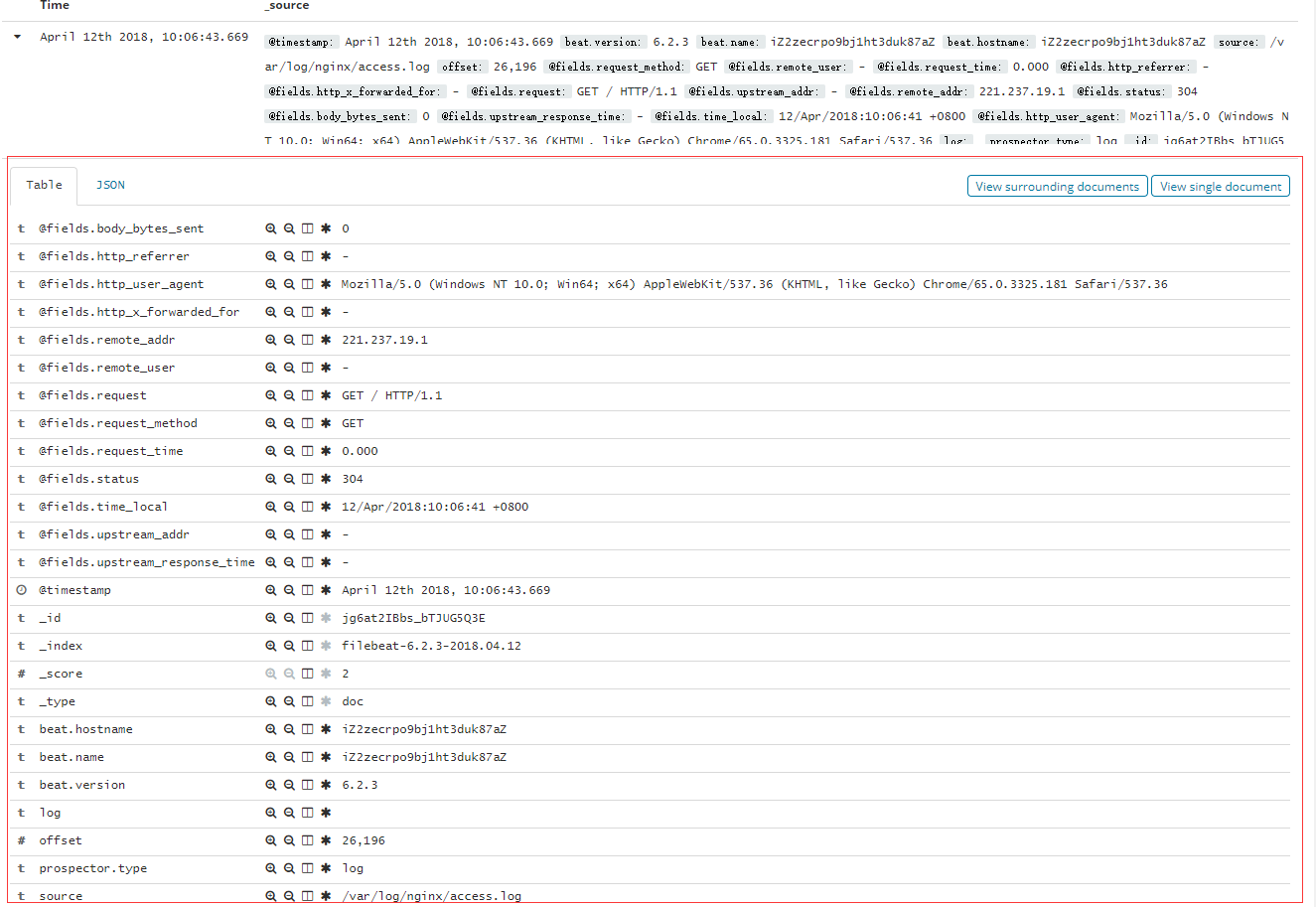
如何自定义索引名称?
上面的例子创建出来的索引都是默认的索引名称filebeat-*, 我需要创建我自己的索引名称,如我收集的是生产系统的nginx日志,我希望叫做nginx-production-* ,可以按照如下设置,我这里直接将nginx的配置配到了一个yml文件里。
cat nginx.yml
filebeat.prospectors:
- type: log
enabled: true
paths:
- /var/log/nginx/access.log
json.message_key: log
json.keys_under_root: true
output.elasticsearch:
hosts: ["172.16.1.2:9200","172.16.1.4:9200"]
index: "nginx-production-%{+yyyy.MM.dd}"
setup.template:
name: "nginx-production"
pattern: "nginx-production-*"
enabled: false启动:./filebeat -c nginx.yml -e
启动后在Kibanna的Management中创建索引就会看到自定义名称的索引了。
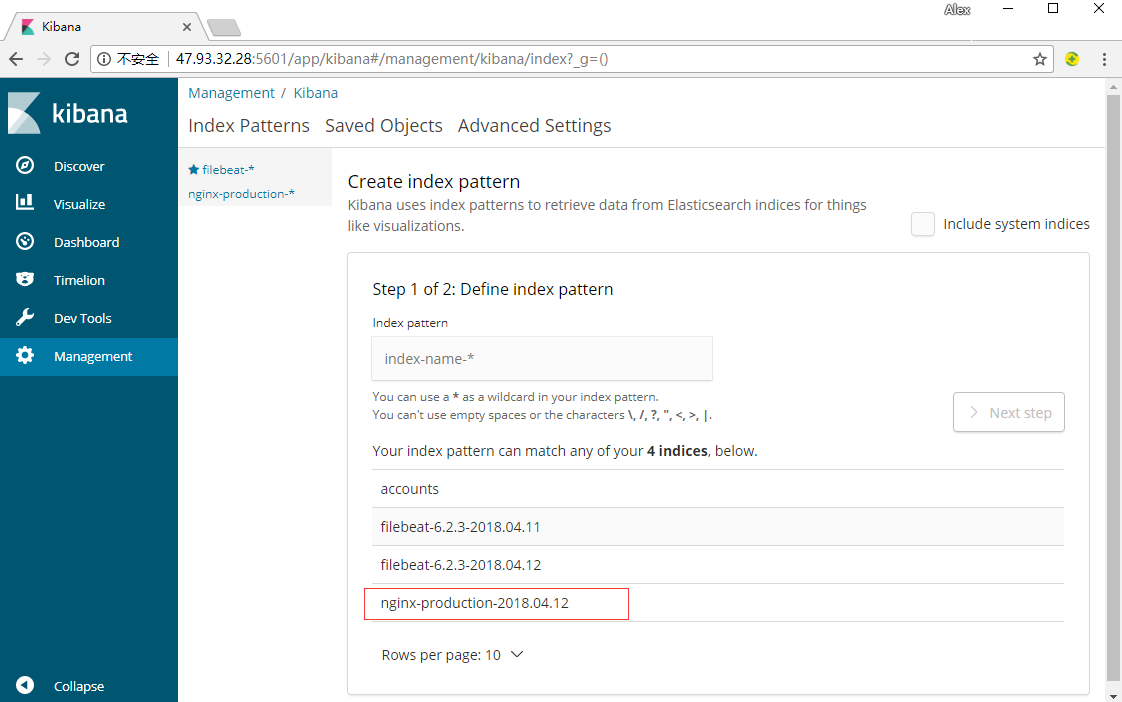
执行和之前第一次创建索引时一样的操作,你就会在Discover中看到信息了。
关于日志收集的一些场景,我这里测试的以下几种:
以下场景不考虑日志格式化的情况。
收集一台机器上的1个日志:
比如只收集nginx日志,这种情况可以单独创建一个nginx.yml的配置文件,内容如下:
默认情况下,使用默认索引名称:
filebeat.prospectors:
- type: log
enabled: true
paths:
- /var/log/nginx/access.log
output.elasticsearch:
hosts: ["172.16.1.2:9200","172.16.1.4:9200"]此时的索引名称为默认的如 filebeat-6.2.3-2018.04.12
使用自定义索引名称;
filebeat.prospectors:
- type: log
enabled: true
paths:
- /var/log/nginx/access.log
output.elasticsearch:
hosts: ["172.16.1.2:9200","172.16.1.4:9200"]
index: "nginx-production-%{+yyyy.MM.dd}"
setup.template:
name: "nginx-production"
pattern: "nginx-production-*"
enabled: false此时的索引名称为 nginx-production-2018.04.12
收集一台机器上的多个日志:
比如这里要同时收集机器上的/var/log/nginx/access.log 和 /var/log/messages
可以使用默认的索引名称,也可以自定义。
使用默认名称:
filebeat.prospectors:
- type: log
enabled: true
paths:
- /var/log/nginx/access.log
- type: log
enabled: true
paths:
- /var/log/messages
output.elasticsearch:
hosts: ["172.16.1.2:9200","172.16.1.4:9200"]使用自定义索引名称:
filebeat.prospectors:
- type: log
enabled: true
paths:
- /var/log/nginx/access.log
- type: log
enabled: true
paths:
- /var/log/messages
output.elasticsearch:
hosts: ["172.16.1.2:9200","172.16.1.4:9200"]
index: "server1-%{+yyyy.MM.dd}"
setup.template:
name: "server1"
pattern: "server1-*"
enabled: false
收集一台机器上的多个日志,并各个日志使用不同索引名称:
还是以同时收集/var/log/nginx/access.log 和 /var/log/messages 为例,这时可以单独分别建立nginx.yml和system.yml两个配置文件,然后分别启动。
nginx.yml
filebeat.prospectors:
- type: log
enabled: true
paths:
- /var/log/nginx/access.log
output.elasticsearch:
hosts: ["172.16.1.2:9200","172.16.1.4:9200"]
index: "nginx-production-%{+yyyy.MM.dd}"
setup.template:
name: "nginx-production"
pattern: "nginx-production-*"
enabled: falsesystem.yml
filebeat.prospectors:
- type: log
enabled: true
paths:
- /var/log/messages
output.elasticsearch:
hosts: ["172.16.1.2:9200","172.16.1.4:9200"]
index: "system-%{+yyyy.MM.dd}"
setup.template:
name: "system-"
pattern: "system-*"
enabled: false
收集多台机器上的同一个日志,使用默认索引名称:
这种场景也比较常见,比如在集群环境中,有2台nginx的日志都要收集。
同时分别在2台机器上创建nginx.yml,然后再2台机器上都启动。
filebeat.prospectors:
- type: log
enabled: true
paths:
- /var/log/nginx/access.log
output.elasticsearch:
hosts: ["172.16.1.2:9200","172.16.1.4:9200"]
收集多台机器上的同一个日志,使用自定义索引名称:
和上面方式一致。
filebeat.prospectors:
- type: log
enabled: true
paths:
- /var/log/nginx/access.log
output.elasticsearch:
hosts: ["172.16.1.2:9200","172.16.1.4:9200"]
index: "nginx-production-%{+yyyy.MM.dd}"
setup.template:
name: "nginx-production"
pattern: "nginx-production-*"
enabled: false
收集多台机器上的多个日志,使用默认索引名称:
方式一样,在各自机器上创建配置文件并启动。
收集多台机器上的多个日志,并各个日志使用自定义名称:
方式一样,在各自机器上创建配置文件并启动。
第四章:Logstash入门
Logstash 是开源的服务器端数据处理管道,能够同时 从多个来源采集数据、转换数据,然后将数据发送到您最喜欢的 “存储库” 中。(我们的存储库当然是 Elasticsearch。)
logstash处理流程:
imput输入:可以接收file、redis、beats、kafka的数据
filter过滤器:可以对收到的数据进行grok、mutate、drop、date
output输出:可以将处理后的数据输出到stdout、elasticsearch、redis、kafka
input和output配置:
最简单的配置:
imput {
file{
path => "/tmp/abc.log"
}
}
output {
stdout{
codec => rubydebug
}
}Filter配置:
Grok:
基于正则表达式提供了丰富可重用的模式(pattern)
基于此可以将非机构化数据做机构化处理
Date
将字符串类型的时间字段转换为时间戳类型,方便后续数据处理
Mutate
进行增加、修改、删除、替换等字段相关的处理
Filter配置Grok示例:
日志示例:
1.2.3.4 GET /index.html 15824 0.043
Grok示例:
%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}
解析后:
{
“client” : "1.2.3.4",
"method" : "GET",
"request" : "/index.html",
"bytes" : 15824,
"duration" : 0.043
}
安装logstash:
这里在server-2上安装:
cd /data/software/
wget https://artifacts.elastic.co/downloads/logstash/logstash-6.2.3.tar.gz
tar -zxvf logstash-6.2.3.tar.gz
mv logstash-6.2.3 /data/app/
cd /data/app/logstash-6.2.3/bin/
配置文件示例,创建一个配置文件logstash.conf
input {
file {
path => "/data/nginx/logs/www.chenxie.net_access.*"
codec => json
type => "chenxie-access-log"
start_position => "beginning"
}
}
output {
if [type] == "chenxie-access-log" {
elasticsearch {
hosts => ["172.16.1.2:9200","172.16.1.4:9200"]
index => "chenxie-access-log-%{+yyyy.MM.dd}"
}
}
}启动:
./logstash -f logstash.conf
启动后便会将数据发送至elasticsearch,在Kibanna添加索引后变可看到结果了。
以上展示了一些基本的用法,对于基本的日志收集应该问题不大了,更多的信息还请访问elastic的官网进行查询。
共有 0 条评论