
Docker Swarm
![]()
什么是 Docker Swarm
详细的解释可以看官方文档:https://docs.docker.com/engine/swarm/
在这之前我们都是在一台服务器上操作Docker,在实际企业中是远远不能满足需求的,企业中所需要的高可用、弹性伸缩等都不能够在单台服务上得到应用,所以我们实践中往往都是需要以集群模式部署,防止单点故障。
Swarm就是一个Docker公司推出的用来管理docker集群的平台,它可以将多台Docker主机组成Swarm集群,在Manager管理节点上实现对集群的管理,服务部署在Swarm集群中,可以很好解决服务高可用、可伸缩的需求,对于服务器不多又需要使用集群的场景,Swarm是个不错的选择,简单且易用。
不过随着不断变化的业务发展,Swarm已逐步被淘汰,目前主流大多为Kubernetes(k8s),Kubernetes所涉及的东西要比Swarm要多得多,但学习Swarm有助于我们后期对Kubernetes的理解,所以还是有必要了解的。
Swarm 工作模式
Node节点工作模式
Docker从1.12版本开始就引入了swarm模式,使你能够创建一个由一个或多个Docker引擎(主机)组成的集群,我们管这个集群叫做swarm集群。
一个swarm集群由一个或多个节点组成,有两种不同类型的节点(Node):manager 管理节点、worker 工作节点。
部署服务时,manager节点和worker节点都可以部署服务。
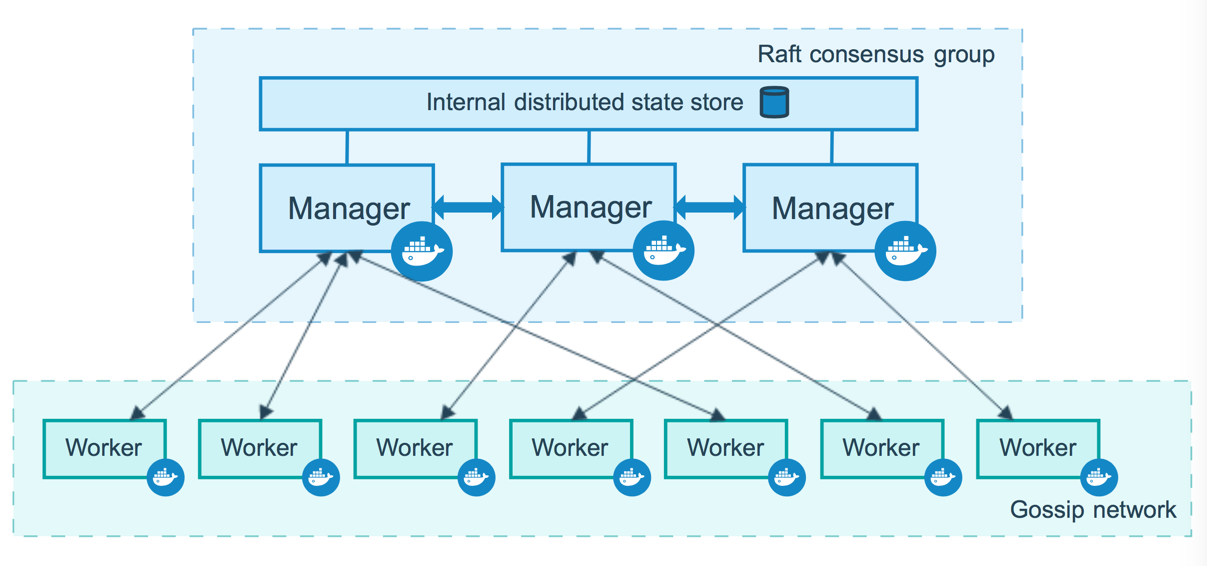
manager 管理节点:
Manager 节点负责处理集群管理任务:
- 维护集群状态
- 调度服务
- 对外提供HTTP API 端点
集群使用Raft实现,Manager维护整个 swarm 和在其上运行的所有服务的一致内部状态。对于测试环境,你的swarm集群可以只有一个manager节点,如果这个集群的manager节点发生故障,你worker节点的服务将继续运行,但无法管理,直到manager节点恢复。
为了利用 swarm 模式的容错特性,Docker 建议根据组织的高可用性要求实现奇数个manager节点。当您有多个manager节点时,您可以从manager节点的故障中恢复而无需停机。
- 集群中有3个manager节点,最多允许1个manager宕机;
- 集群中有5个manager节点,最多允许2个manager宕机;
- 集群中有N个manager节点,最多允许
(N-1)/2个manager宕机; - Docker 建议一个 swarm 最多使用7个manger节点。
worker 工作节点:
工作节点也是 Docker 引擎的实例,其唯一目的是执行容器。Worker 节点不参与 Raft 分布式状态,不做调度决策,也不服务于 swarm 模式的 HTTP API。
您可以创建一个由1个manger节点组成的集群,如果没有至少1个manger节点,您就不能拥有1个worker节点。默认情况下,所有manger节点也是worker节点。在单个manger节点集群中,您可以运行类似docker service create的命令,并且调度程序将所有任务放在本地引擎上。
要防止调度程序将任务放置在多节点集群中的manager节点上,请将manager节点的可用性设置为Drain。调度器优雅地停止Drain模式节点上的任务,并在一个 Active节点上调度任务。调度程序不会将新任务分配给Drain 可用的节点。
请参阅docker node update 命令行参考以了解如何更改节点可用性。
services 工作模式
要在swarm中部署应用程序的镜像,需要首先创建一个服务(service),创建服务时,需要指定要运行的容器镜像以及在容器中执行的命令,此外还可以定义一些其他选项,如:端口映射、网络、CPU内存限制、滚动更新策略、副本数等。
服务、任务和容器
当您将服务部署到 swarm 时,swarm 管理节点接受您的服务定义作为服务的所需状态。然后,它将集群中的节点上的服务安排为一个或多个副本任务。这些任务在 swarm 中的节点上彼此独立运行。
例如,假设您想在nginx的三个实例之间进行负载平衡。下图显示了具有三个副本的 nginx服务。侦听器的三个实例中的每一个都是 swarm 中的一个任务。

容器是一个独立的进程。在 swarm 模式模型中,每个任务只调用一个容器。任务类似于调度程序放置容器的“槽”。一旦容器处于活动状态,调度程序就会识别出任务处于运行状态。如果容器未通过健康检查或终止,则任务终止。
Swarm 集群搭建
下面我们将进行Swarm集群搭建,我们将使用4台主机分别搭建并测试:1manger+3worker、3manger+1worker 的集群架构。
主机规划
| 主机名 | IP |
| docker-1 | 192.168.92.130 |
| docker-2 | 192.168.92.152 |
| docker-3 | 192.168.92.153 |
| docker-4 | 192.168.92.154 |
修改主机名:
hostnamectl set-hostname docker-1 hostnamectl set-hostname docker-2 hostnamectl set-hostname docker-3 hostnamectl set-hostname docker-4
关闭防火墙:
systemctl stop firewalld systemctl disable firewalld
安装 Docker环境
分别在4台服务器上安装Docker环境,安装教程:CentOS 7 安装 Docker-CE 并配置阿里云加速器
集群搭建
集群搭建主要为2步:
- 初始化集群:docker swarm init --advertise-addr IPaddress
- 节点加入集群:docker swarm join-token manager/worker 获取加入集群成为manager/worker节点的令牌
Swarm命令:
[root@docker-1 ~]# docker swarm --help Usage: docker swarm COMMAND Manage Swarm Commands: ca Display and rotate the root CA init Initialize a swarm # 初始化swarm集群 join Join a swarm as a node and/or manager # 加入swarm集群 join-token Manage join tokens # 获取加入集群的token leave Leave the swarm # 从swarm集群中移除 unlock Unlock swarm unlock-key Manage the unlock key update Update the swarm Run 'docker swarm COMMAND --help' for more information on a command.
初始化swarm集群:
[root@docker-1 ~]# docker swarm init --help
Usage: docker swarm init [OPTIONS]
Initialize a swarm
Options:
--advertise-addr string Advertised address (format: <ip|interface>[:port])
......
1manger+3worker 集群搭建
这里我们选择 docker-1 为管理节点,在此主机上初始化管理节点,192.168.92.130 为当前操作主机的IP
[root@docker-1 ~]# docker swarm init --advertise-addr 192.168.92.130
Swarm initialized: current node (vjq4rfdu2jr1peg56dr13hc1o) is now a manager.
To add a worker to this swarm, run the following command:
# 在其他主机上运行此命令加入到集群成为worker节点
docker swarm join --token SWMTKN-1-2tq4pgnc25y38ppx4osw1afxxcsmktcfxl4582k3y0v0qt992i-25zvr62tu4af0ukq20cnx3l7f 192.168.92.130:2377
To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
这里得到了一条带令牌的命令,在其他主机上运行此命令即可加入到swarm集群中成为worker节点。
如果上面的命令忘记或遗失,可以通过下面两个命令获取:
docker swarm join-token manager # 获取加入swarm集群成为 管理节点 的令牌 docker swarm join-token worker # 获取加入swarm集群成为 工作节点 的令牌
在docker-2、docker-3、docker-4上运行此命令,将docker-2、docker-3、docker-4加入集群使之成为worker节点。
[root@docker-2 ~]# docker swarm join --token SWMTKN-1-2tq4pgnc25y38ppx4osw1afxxcsmktcfxl4582k3y0v0qt992i-25zvr62tu4af0ukq20cnx3l7f 192.168.92.130:2377 This node joined a swarm as a worker.
[root@docker-3 ~]# docker swarm join --token SWMTKN-1-2tq4pgnc25y38ppx4osw1afxxcsmktcfxl4582k3y0v0qt992i-25zvr62tu4af0ukq20cnx3l7f 192.168.92.130:2377 This node joined a swarm as a worker.
[root@docker-4 ~]# docker swarm join --token SWMTKN-1-2tq4pgnc25y38ppx4osw1afxxcsmktcfxl4582k3y0v0qt992i-25zvr62tu4af0ukq20cnx3l7f 192.168.92.130:2377 This node joined a swarm as a worker.
查看集群信息:
在docker-1上,只能在manger管理节点上查看:
[root@docker-1 ~]# docker node ls ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION vjq4rfdu2jr1peg56dr13hc1o * docker-1 Ready Active Leader 20.10.12 iwem4frtz0rjhfh3p9gldb7nq docker-2 Ready Active 20.10.12 oj7xmee9o0pkbcsu81x9uf0nq docker-3 Ready Active 20.10.12 nyzvunyg368lmgw8zy3dq09ct docker-4 Ready Active 20.10.12
此时可以看到我们已经搭建起了一个 1manager+3worker的集群。
1manager+3worker 虽然也可以正常工作,但是一旦唯一个一个manager宕机后,整个集群就无法工作了。此架构可用于测试,不可用于生产。
3manager+1worker集群搭建
接下来我们将架构改为 3manager+1worker的架构。这种架构可以允许1台manager宕机,整个集群依然工作。
我们将 docker-2、docker-3从worker节点改为manager节点:
1. 在docker-1主节点上运行 docker swarm join-token manager 获取加入swarm集群成为 管理节点 的令牌:
[root@docker-1 ~]# docker swarm join-token manager
To add a manager to this swarm, run the following command:
# 加入到swarm集群成为manager节点的令牌
docker swarm join --token SWMTKN-1-2tq4pgnc25y38ppx4osw1afxxcsmktcfxl4582k3y0v0qt992i-09f8pehylp76xf3fvmqdsu02k 192.168.92.130:2377
2. 在docker-2、docker-3上首先运行 docker swarm leave 离开集群,再运行docker-1上获取的加入集群成为manager节点的token
# 离开集群 [root@docker-2 ~]# docker swarm leave Node left the swarm. # 加入集群并成为manager [root@docker-2 ~]# docker swarm join --token SWMTKN-1-2tq4pgnc25y38ppx4osw1afxxcsmktcfxl4582k3y0v0qt992i-09f8pehylp76xf3fvmqdsu02k 192.168.92.130:2377 This node joined a swarm as a manager.
# 离开集群 [root@docker-3 ~]# docker swarm leave Node left the swarm. # 加入集群并成为manager [root@docker-3 ~]# docker swarm join --token SWMTKN-1-2tq4pgnc25y38ppx4osw1afxxcsmktcfxl4582k3y0v0qt992i-09f8pehylp76xf3fvmqdsu02k 192.168.92.130:2377 This node joined a swarm as a manager.
3. 查看集群信息:
[root@docker-1 ~]# docker node ls ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION vjq4rfdu2jr1peg56dr13hc1o * docker-1 Ready Active Leader 20.10.12 iwem4frtz0rjhfh3p9gldb7nq docker-2 Down Active 20.10.12 r1lvb783up5gx1cce7hqupqff docker-2 Ready Active Reachable 20.10.12 kbbqdd5ioypjwgos3redff6mu docker-3 Ready Active Reachable 20.10.12 oj7xmee9o0pkbcsu81x9uf0nq docker-3 Down Active 20.10.12 nyzvunyg368lmgw8zy3dq09ct docker-4 Ready Active 20.10.12
此时可以看到就是一个3manager+1worker节点的集群架构。3个manager中一个是Leader、另外两个是 Reachable,当Leader挂掉的时候,则会根据Raft一致性算法从这两个Reachable的节点中选择一个成为Leader继续管理整个集群。
4. 同时可以看到里面有显示 docker-2、docker-3 状态为Down,这是因为运行了 docker swarm leave 的结果,运行之后节点就会变成Down,但并不会真正移除出集群,只是告知集群暂时离开了,真正从集群中移除需要执行 docker node rm 移除节点,如下:
# 移除docker-2 [root@docker-1 ~]# docker node rm iwem4frtz0rjhfh3p9gldb7nq iwem4frtz0rjhfh3p9gldb7nq # 移除docker-3 [root@docker-1 ~]# docker node rm oj7xmee9o0pkbcsu81x9uf0nq oj7xmee9o0pkbcsu81x9uf0nq # 再次查看集群节点信息 [root@docker-1 ~]# docker node ls ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION vjq4rfdu2jr1peg56dr13hc1o * docker-1 Ready Active Leader 20.10.12 r1lvb783up5gx1cce7hqupqff docker-2 Ready Active Reachable 20.10.12 kbbqdd5ioypjwgos3redff6mu docker-3 Ready Active Reachable 20.10.12 nyzvunyg368lmgw8zy3dq09ct docker-4 Ready Active 20.10.12
Raft一致性算法
接下来我们来验证一下集群Raft一致性算法下的管理节点变化过程。
1. 将docker-1关机,模拟宕机,然后在另外两个主节点上查看集群情况:
[root@docker-2 ~]# docker node ls ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION vjq4rfdu2jr1peg56dr13hc1o docker-1 Down Active Unreachable 20.10.12 r1lvb783up5gx1cce7hqupqff * docker-2 Ready Active Leader 20.10.12 kbbqdd5ioypjwgos3redff6mu docker-3 Ready Active Reachable 20.10.12 nyzvunyg368lmgw8zy3dq09ct docker-4 Ready Active 20.10.12
可以看到docker变成了 Down 并且 Unreachable状态,docker-2被选择为了新的 Leader.
2. 接下来我们继续将docker-3关机,模拟宕机,来看看集群情况:
[root@docker-2 ~]# docker node ls Error response from daemon: rpc error: code = Unknown desc = The swarm does not have a leader. It's possible that too few managers are online. Make sure more than half of the managers are online.
再次查看集群状态可以看到,虽然我们将docke-3停掉,按理说集群中还有docker-2是manager节点,并且是Leader,集群应该可以正常工作才是,但结果却不是那样的。
因为我们是一个3manger的集群,那么Raft一致性算法要求我们必须确保半数以上的manager节点在线,也就是3台manager必须有2台在线,5台manager必须有3台在线,那整个集群才能够正常的工作。
3. 重新将 docker-1、docker-3开机,再查看集群:
启动之后,集群正常工作了。
[root@docker-2 ~]# docker node ls ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION vjq4rfdu2jr1peg56dr13hc1o docker-1 Ready Active Reachable 20.10.12 r1lvb783up5gx1cce7hqupqff * docker-2 Ready Active Leader 20.10.12 kbbqdd5ioypjwgos3redff6mu docker-3 Ready Active Reachable 20.10.12 nyzvunyg368lmgw8zy3dq09ct docker-4 Ready Active 20.10.12
服务管理
Swarm特点:弹性、扩缩容
之前操作的 docker run 、docker-compose up 启动一个一项目,都是单机的;现在使用swarm集群,通过 docker service 来管理
之前单机:一个service就是指向的一个容器,比如一个 nginx服务指向一个nginx容器;
现在集群 :一个service可能指向一个或多个容器,比如对外暴露了一个nginx服务,实际上后端有多个nginx容器构成(就像负载均衡)。
命令:
[root@docker-1 ~]# docker service --help Usage: docker service COMMAND Manage services Commands: create Create a new service # 创建一个服务 inspect Display detailed information on one or more services # 查看服务详细信息 logs Fetch the logs of a service or task # 查看日志 ls List services ps List the tasks of one or more services rm Remove one or more services # 移除服务 rollback Revert changes to a service's configuration scale Scale one or multiple replicated services # 伸缩一个或多个副本 update Update a service # 更新服务 Run 'docker service COMMAND --help' for more information on a command.
创建服务:
[root@docker-1 ~]# docker service create -p 8888:80 --name my-nginx nginx pvom9t9zbdkh3uk42jj3q06np overall progress: 1 out of 1 tasks 1/1: running [==================================================>] verify: Service converged
查看服务:
# 通过 docker service ls 可以看到有哪些service在集群上 # 当前只有一个 my-nginx service,当前只有1个副本,总共1个副本 [root@docker-1 ~]# docker service ls ID NAME MODE REPLICAS IMAGE PORTS pvom9t9zbdkh my-nginx replicated 1/1 nginx:latest *:8888->80/tcp # 通过 docker service ps my-nginx 可以查看执行的service部署情况 # 当前运行在 docker-3 机器上 [root@docker-1 ~]# docker service ps my-nginx ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS rdz0t33xdvxx my-nginx.1 nginx:latest docker-3 Running Running 5 minutes ago
当前my-nginx服务中,真正nginx容器运行在docker-3上,docker-1虽然是manager节点,但也能跑服务。
访问测试:
尽管真正的nginx容器运行的docker-3上,但是由于是采用集群部署模式,此时无论使用集群中的哪个主机IP访问8888端口都能够访问到nginx服务。
http://192.168.92.130:8888/
http://192.168.92.152:8888/
http://192.168.92.153:8888/
http://192.168.92.154:8888/
扩缩容
两个方式:
- docker service update
- docker service scale
当前my-nginx只有1个副本,现在给它扩到3个,使用 docker service update --replicas 3 my-nginx
[root@docker-1 ~]# docker service update --replicas 3 my-nginx my-nginx overall progress: 3 out of 3 tasks 1/3: running [==================================================>] 2/3: running [==================================================>] 3/3: running [==================================================>] verify: Service converged [root@docker-1 ~]# docker service ls ID NAME MODE REPLICAS IMAGE PORTS pvom9t9zbdkh my-nginx replicated 3/3 nginx:latest *:8888->80/tcp # 3个nginx副本分别在 docker-1、docker-3、docker-4机器上各自启动了一个容器 [root@docker-1 ~]# docker service ps my-nginx ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS rdz0t33xdvxx my-nginx.1 nginx:latest docker-3 Running Running 17 minutes ago m2h63c6g4aee my-nginx.2 nginx:latest docker-1 Running Running 48 seconds ago v0t9kqfplu9f my-nginx.3 nginx:latest docker-4 Running Running 42 seconds ago
访问测试:
尽管docker-2上没有部署nginx容器,但是由于是采用集群部署模式,此时无论使用集群中的哪个主机IP访问8888端口都能够访问到nginx服务,包括docker-2。
http://192.168.92.130:8888/
http://192.168.92.152:8888/
http://192.168.92.153:8888/
http://192.168.92.154:8888/
扩到10个:
[root@docker-1 ~]# docker service update --replicas 10 my-nginx my-nginx overall progress: 10 out of 10 tasks 1/10: running [==================================================>] 2/10: running [==================================================>] 3/10: running [==================================================>] 4/10: running [==================================================>] 5/10: running [==================================================>] 6/10: running [==================================================>] 7/10: running [==================================================>] 8/10: running [==================================================>] 9/10: running [==================================================>] 10/10: running [==================================================>] verify: Service converged [root@docker-1 ~]# docker service ps my-nginx ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS rdz0t33xdvxx my-nginx.1 nginx:latest docker-3 Running Running 22 minutes ago m2h63c6g4aee my-nginx.2 nginx:latest docker-1 Running Running 5 minutes ago v0t9kqfplu9f my-nginx.3 nginx:latest docker-4 Running Running 4 minutes ago tcfx6gcwcmwe my-nginx.4 nginx:latest docker-4 Running Running 39 seconds ago pmi5gdg62wsg my-nginx.5 nginx:latest docker-1 Running Running 39 seconds ago jvu3wmhpv7q2 my-nginx.6 nginx:latest docker-2 Running Running 19 seconds ago nycvkr4ffnah my-nginx.7 nginx:latest docker-3 Running Running 38 seconds ago fr6nmwmkel41 my-nginx.8 nginx:latest docker-2 Running Running 19 seconds ago u78vj5easfq0 my-nginx.9 nginx:latest docker-2 Running Running 19 seconds ago ck5p63zoqsq6 my-nginx.10 nginx:latest docker-3 Running Running 38 seconds ago
减到1个:
[root@docker-1 ~]# docker service update --replicas 1 my-nginx my-nginx overall progress: 1 out of 1 tasks 1/1: running [==================================================>] verify: Service converged [root@docker-1 ~]# docker service ps my-nginx ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS rdz0t33xdvxx my-nginx.1 nginx:latest docker-3 Running Running 22 minutes ago
[root@docker-1 ~]# docker service scale my-nginx=4 my-nginx scaled to 4 overall progress: 4 out of 4 tasks 1/4: running [==================================================>] 2/4: running [==================================================>] 3/4: running [==================================================>] 4/4: running [==================================================>] verify: Service converged [root@docker-1 ~]# docker service ps my-nginx ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS rdz0t33xdvxx my-nginx.1 nginx:latest docker-3 Running Running 24 minutes ago kbzanlwvfffq my-nginx.2 nginx:latest docker-4 Running Running 19 seconds ago y1bkw76cnsxh my-nginx.3 nginx:latest docker-2 Running Running 19 seconds ago jqtazzjq715c my-nginx.4 nginx:latest docker-1 Running Running 19 seconds ago
综上:使用swarm扩缩容真的是轻轻松松。
故障转移
当前在每台主机上都运行着一个nginx容器,我们停止docker-4上的nginx容器,模拟容器出现故障。
[root@docker-4 ~]# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 99c0465704ba nginx:latest "/docker-entrypoint.…" 3 minutes ago Up 3 minutes 80/tcp my-nginx.2.kbzanlwvfffqm4eu2nr9m390u [root@docker-4 ~]# docker stop 99c0465704ba 99c0465704ba
再来看看service运行情况:
[root@docker-1 ~]# docker service ps my-nginx ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS rdz0t33xdvxx my-nginx.1 nginx:latest docker-3 Running Running 27 minutes ago 0l0h4vh4tw79 my-nginx.2 nginx:latest docker-4 Running Running 8 seconds ago kbzanlwvfffq \_ my-nginx.2 nginx:latest docker-4 Shutdown Complete 14 seconds ago y1bkw76cnsxh my-nginx.3 nginx:latest docker-2 Running Running 3 minutes ago jqtazzjq715c my-nginx.4 nginx:latest docker-1 Running Running 3 minutes ago
可以看到docker-4上的nginx容器已经 Shutdown了,自动在docker-4上重建了一个新的nginx容器。
再次停止docker-4上重建的nginx容器,再次查看service运行情况,依然是在docker-4上重建的:
[root@docker-1 ~]# docker service ps my-nginx ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS rdz0t33xdvxx my-nginx.1 nginx:latest docker-3 Running Running 30 minutes ago 5121f134n75t my-nginx.2 nginx:latest docker-4 Running Running 49 seconds ago 0l0h4vh4tw79 \_ my-nginx.2 nginx:latest docker-4 Shutdown Complete 55 seconds ago kbzanlwvfffq \_ my-nginx.2 nginx:latest docker-4 Shutdown Complete 3 minutes ago y1bkw76cnsxh my-nginx.3 nginx:latest docker-2 Running Running 6 minutes ago jqtazzjq715c my-nginx.4 nginx:latest docker-1 Running Running 6 minutes ago
是不是停止哪个机器上的容器就在哪个机器上重建呢?
直接将docker-4主机关机,再查看:
此时docker-4上的nginx容器,自动转移到了docker-3主机上,并不受主机的影响,会在集群中自动调度。
[root@docker-1 ~]# docker service ps my-nginx ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS rdz0t33xdvxx my-nginx.1 nginx:latest docker-3 Running Running 31 minutes ago rsfjw6pck39l my-nginx.2 nginx:latest docker-3 Running Starting less than a second ago 5121f134n75t \_ my-nginx.2 nginx:latest docker-4 Shutdown Running 2 minutes ago 0l0h4vh4tw79 \_ my-nginx.2 nginx:latest docker-4 Shutdown Complete 2 minutes ago kbzanlwvfffq \_ my-nginx.2 nginx:latest docker-4 Shutdown Complete 4 minutes ago y1bkw76cnsxh my-nginx.3 nginx:latest docker-2 Running Running 7 minutes ago jqtazzjq715c my-nginx.4 nginx:latest docker-1 Running Running 7 minutes ago
使用 docker service rm
[root@docker-1 ~]# docker service rm my-nginx my-nginx [root@docker-1 ~]# docker service ls ID NAME MODE REPLICAS IMAGE PORTS
镜像变更/升级
重新新建service来测试:
docker service create -p 8888:80 --name my-nginx nginx
# 将镜像变更为 nginx:1.20 [root@docker-1 ~]# docker service update --image nginx:1.20 my-nginx my-nginx overall progress: 1 out of 1 tasks 1/1: running [==================================================>] verify: Service converged
# 老镜像nginx:latest停止,新镜像nginx:1.20启用 [root@docker-1 ~]# docker service ps my-nginx ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS z2gmcjtljhqg my-nginx.1 nginx:1.20 docker-3 Running Running about a minute ago svh5jpysqcc3 \_ my-nginx.1 nginx:latest docker-3 Shutdown Shutdown about a minute ago
回滚到上个版本
# 回滚到上个版本 [root@docker-1 ~]# docker service update --rollback my-nginx my-nginx rollback: manually requested rollback overall progress: rolling back update: 1 out of 1 tasks 1/1: running [> ] verify: Service converged [root@docker-1 ~]# docker service ps my-nginx ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS xak0904ma7wf my-nginx.1 nginx:latest docker-1 Running Running 12 seconds ago z2gmcjtljhqg \_ my-nginx.1 nginx:1.20 docker-3 Shutdown Shutdown 13 seconds ago svh5jpysqcc3 \_ my-nginx.1 nginx:latest docker-3 Shutdown Shutdown 6 minutes ago
删除service:
[root@docker-1 ~]# docker service rm my-nginx my-nginx
更多使用用法请看:
docker service update --help
数据卷挂载
我们之前已经学习过在容器中使用volume数据卷,这里我们来看看如何在swarm集群中使用数据卷。
volume数据卷
创建一个新的数据卷:
[root@docker-1 ~]# docker volume create my-volume
my-volume
[root@docker-1 ~]# docker volume ls
DRIVER VOLUME NAME
local my-volume
[root@docker-1 ~]# docker volume inspect my-volume
[
{
"CreatedAt": "2022-03-10T16:45:01+08:00",
"Driver": "local",
"Labels": {},
"Mountpoint": "/var/lib/docker/volumes/my-volume/_data",
"Name": "my-volume",
"Options": {},
"Scope": "local"
}
]
创建一个service并使用数据库挂载:
# 创建service并使用volume挂载 # src可写为source,dst可写为target [root@docker-1 ~]# docker service create --replicas 3 --mount type=volume,src=my-volume,dst=/vol_test --name my-nginx nginx frar0fbts1f3ezwyttweoa10r overall progress: 3 out of 3 tasks 1/3: running [==================================================>] 2/3: running [==================================================>] 3/3: running [==================================================>] verify: Service converged [root@docker-1 ~]# docker service ls ID NAME MODE REPLICAS IMAGE PORTS frar0fbts1f3 my-nginx replicated 3/3 nginx:latest [root@docker-1 ~]# docker service ps my-nginx ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS jbz6e1w0ce7n my-nginx.1 nginx:latest docker-1 Running Running 18 seconds ago q4fuyxb7ctph my-nginx.2 nginx:latest docker-3 Running Running 17 seconds ago f3ce25vrbrpb my-nginx.3 nginx:latest docker-2 Running Running 18 seconds ago
在3个主机上部署了nginx容器,查看有没有挂载成功,我们逐个登录主机进入容器查看:
首先看docker-1机器:
[root@docker-1 ~]# docker exec -it 7865bec81dce /bin/bash root@7865bec81dce:/# ls /vol_test/ root@7865bec81dce:/# echo "This is volume test from docker-1" > /vol_test/docker-1.txt root@7865bec81dce:/# ls /vol_test/ docker-1.txt root@7865bec81dce:/# exit exit [root@docker-1 ~]# ls /var/lib/docker/volumes/my-volume/_data/ docker-1.txt [root@docker-1 ~]# cat /var/lib/docker/volumes/my-volume/_data/docker-1.txt This is volume test from docker-1
再来看 docker-2、docker-3 发现,我们在docker-1容器里创建的文件,docker-2、docker-3的容器里并没有,说明通过此方式挂载的数据卷只能用于本地,是不能够共享的。
另一种挂载方式:
语法: docker service create --mount type=bind,source=/host_dir,target=/container_dir # source路径要求在部署的目标机器上真实存在,比如部署3个副本有可能分部在不同主机,那每个主机上都必须要存在此目录
示例:
[root@docker-1 ~]# docker service create --mount type=bind,source=/opt/web,target=/usr/share/nginx/html -p 8888:80 --name my-nginx nginx mumiyabkxyceeymzmkeoz637q overall progress: 1 out of 1 tasks 1/1: running [==================================================>] verify: Service converged [root@docker-1 ~]# docker service ls ID NAME MODE REPLICAS IMAGE PORTS mumiyabkxyce my-nginx replicated 1/1 nginx:latest *:8888->80/tcp [root@docker-1 ~]# docker service ps my-nginx ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS jwmr1e9zn1uk my-nginx.1 nginx:latest docker-3 Running Running 33 seconds ago
部署到了docker-3.
在docker-3机器上 /opt/web/目录下创建一个index.html 文件:
[root@docker-3 ~]# echo "This is test from docker-3" > /opt/web/index.html [root@docker-3 ~]# ls /opt/web/ index.html
访问测试:
使用任意主机IP访问8888端口:
[root@docker-1 ~]# curl http://192.168.92.153:8888 This is test from docker-3
删除service:
[root@docker-1 ~]# docker service rm my-nginx my-nginx
小总结:
通过以上对数据卷的操作案例可以看出,数据卷之间的数据是不能够在集群中共享的,对于集群部署意义并不大,如果能共享数据才是极好的,可以使用nfs解决。
通过nfs在集群中共享数据:
我们需要用一台服务器当作nfs服务器,这里我们把docker-4当作nfs服务器,在docker-4上安装nfs服务。
yum install nfs-utils -y mkdir -p /data/nfs # 编辑 /etc/exports 文件,内容如下 [root@docker-4 ~]# cat /etc/exports /data/nfs 192.168.92.0/24(rw,no_root_squash) # 启动nfs systemctl start nfs systemctl enable nfs
创建服务:
[root@docker-1 ~]# docker service create --mount 'type=volume,source=nfsvolume,target=/usr/share/nginx/html,volume-driver=local,volume-opt=type=nfs,volume-opt=device=:/data/nfs,"volume-opt=o=addr=192.168.92.154,rw,nfsvers=4,async"' --replicas 4 -p 8888:80 --name my-nginx nginx vqxjrbz91rdy9yutgnfmt2icc overall progress: 4 out of 4 tasks 1/4: running [==================================================>] 2/4: running [==================================================>] 3/4: running [==================================================>] 4/4: running [==================================================>] verify: Service converged [root@docker-1 ~]# [root@docker-1 ~]# docker service ls ID NAME MODE REPLICAS IMAGE PORTS vqxjrbz91rdy my-nginx replicated 4/4 nginx:latest *:8888->80/tcp [root@docker-1 ~]# [root@docker-1 ~]# docker service ps my-nginx ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS yuwkqgd3mlyb my-nginx.1 nginx:latest docker-3 Running Running 15 seconds ago h6n3t2v9c04x my-nginx.2 nginx:latest docker-2 Running Running 16 seconds ago igoqir801uhu my-nginx.3 nginx:latest docker-4 Running Running 16 seconds ago 3jibweokor60 my-nginx.4 nginx:latest docker-1 Running Running 16 seconds ago
查看volume:
[root@docker-1 ~]# docker volume ls
DRIVER VOLUME NAME
local nfsvolume
[root@docker-1 ~]#
[root@docker-1 ~]# docker volume inspect nfsvolume
[
{
"CreatedAt": "2022-03-10T17:44:05+08:00",
"Driver": "local",
"Labels": {},
"Mountpoint": "/var/lib/docker/volumes/nfsvolume/_data",
"Name": "nfsvolume",
"Options": {
"device": ":/data/nfs",
"o": "addr=192.168.92.154,rw,nfsvers=4,async",
"type": "nfs"
},
"Scope": "local"
}
]
每个机器上都自动创建了 nfsvolume 数据卷。
访问测试:
在 docker-4 上向/data/nfs/目录下创建一个index.html文件
[root@docker-4 ~]# echo "This is nfs volume test from docker-4" > /data/nfs/index.html
访问:
[root@docker-1 ~]# curl http://192.168.92.130:8888 This is nfs volume test from docker-4
成功访问到,成功。
多服务Swarm集群部署
前面我们操作的都是单个服务在swarm集群中部署,那如果要一次部署多个服务呢?
实际上我们可以利用compose来实现,compose默认只是针对多个服务在单机上批量部署的,但我们可以利用到compose中的deploy来定义在集群中如何部署。
关于deploy的官方文档: https://docs.docker.com/compose/compose-file/compose-file-v3/#deploy
deploy 部分的配置只在使用 docker stack deploy 部署到swarm集群中有效,使用 docker-compose 和 docker-compose run 时,deploy部分的配置将会忽略不会被执行。
如下 compose.yml
version: "3.9"
services:
redis:
image: redis:alpine
deploy:
replicas: 6
placement:
max_replicas_per_node: 1
update_config:
parallelism: 2
delay: 10s
restart_policy:
condition: on-failure
启动部署并查看:
# 启动部署 [root@docker-1 ~]# docker stack deploy -c compose.yml up Creating network up_default Creating service up_redis # 看到共计6个副本,成功了4个,因为 (max 1 per node) 每一个节点最多只运行1个副本,这里我们只有4个节点,所以只有4个副本运行成功 [root@docker-1 ~]# docker service ls ID NAME MODE REPLICAS IMAGE PORTS p0pn2w313tob up_redis replicated 4/6 (max 1 per node) redis:alpine # 每个node上只有一个副本在运行,因为compose.yml中定义了 max_replicas_per_node: 1 每一个节点最多只运行1个副本,这里我们只有4个节点,所以看到有两个失败 [root@docker-1 ~]# docker service ps up_redis ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS t9b1s57ckrqq up_redis.1 redis:alpine docker-2 Running Running about a minute ago 56oplb1h7n3e up_redis.2 redis:alpine docker-4 Running Running about a minute ago layzi9ggfu4u up_redis.3 redis:alpine docker-3 Running Running about a minute ago y67mnxyppjcb up_redis.4 redis:alpine Running Pending about a minute ago "no suitable node (max replica…" 56ouwyy0akwi up_redis.5 redis:alpine Running Pending about a minute ago "no suitable node (max replica…" sa8qso0r9m50 up_redis.6 redis:alpine docker-1 Running Running about a minute ago
共有 0 条评论